2022. 11. 30. 16:58ㆍPython
이전까지 Python 기본 문법을 학습하고 공공데이터를 받아 가공해서 지도와 결합하는 실습도 해보았습니다.
제가 생각할 때 Python은 데이터 가공에 특화된 언어라고 생각하는데요,
그래서 이번 포스팅에서는 xlsxwriter 라이브러리를 이용해서 row데이터를 읽은 후 데이터 가공을 해보려 합니다.
우선 생소한 개념인 xlsxwriter부터 짚어보겠습니다.
xlsxwriter란?
텍스트, 숫자 및 수식을 여러 워크시트에 입력하는 데 사용할 수 있으며, 서식, 이미지, 차트, 페이지 설정, 자동 필터,
조건부 서식 및 기타 여러 기능을 지원하는 모듈(라이브러리)입니다.
다른 모듈에 비해 다양한 기능을 지원하고 빠른 속도와 적은 메모리를 사용하는 장점이 있습니다.
Excel과 xlsxwriter의 구성
Excel은 Workbook, Worksheet, Cell로 구성되어 있습니다. xlsxwriter는 이 개념을 그대로 사용하여 Python에서 활용할 수 있도록 해줍니다.
1) Workbook
하나의 Excel 파일로 생각하면 됩니다. Workbook안에는 Worksheet 생성이 가능하고 Excel과 같이 여러 Worksheet를 생성한 후 선택하여 작업이 가능합니다.
2) Worksheet
Workbook 내에 포함됩니다. Worksheet를 생성하면 그 안에 포함되는 Cell에 값을 입력하는 등 작업이 가능합니다.
3) Cell
Worksheet에는 Row(행)와 Column(열)으로 구분되어 있습니다. 이를 통해 각각의 칸에 접근할 수 있는데 이 단위를 Cell이라고 합니다.
엑셀의 최대 행과 열의 개수는 65535입니다. 몇 만 건 몇 십만 건의 데이터를 다룰 가능성이 있다면 Python으로 가공 후 xlsxwriter 라이브러리를 활용하는 것을 추천합니다. (보고서 형태로 뽑을 수도 있습니다.)
실습은 구글 콜랩으로 진행하였습니다.
설치
!pip install xlsxwriter만약 설치가 안된다면, PowerShell를 관리자 권한으로 열고 pip install xlsxwriter 엔터를 치면 정상적으로 설치가 완료됩니다.
import xlsxwriter
Python에서 xlsxwriter라이브러리를 활용하기 위해서 import 해줍니다.
import를 통해 xlsxwriter를 불러오고 엑셀 파일을 만들 수 있습니다.
import xlsxwriter
1.1 Cell에 문자열과 숫자를 입력하는 방법
이제 Workbook과 Worksheet를 생성하고 Cell에 문자열과 숫자를 입력해보겠습니다.
# 엑셀 파일 생성
workbook = xlsxwriter.Workbook('examplel1_1.xlsx')
# 엑셀 파일 안에 워크 시트 생성
worksheet = workbook.add_worksheet('leacoding')
# Cell안에 문자값 입력하기1
worksheet.write('A1', 'A') # A1자리에 A를 적겠다
worksheet.write('B1', 'B')
worksheet.write('C1', 'C')
worksheet.write('D1', 'D')
worksheet.write('E1', 'E')
# Cell안에 숫자값 입력하기1
worksheet.write('A2', 1)
worksheet.write('B2', 2)
worksheet.write('C2', 3)
worksheet.write('D2', 4)
worksheet.write('E2', 5)
# Cell안에 문자값 입력하기2
# 좌표로 셀 안에 문자값 입력하기(시작 index는 0부터) (row, column, 입력할 값)
worksheet.write(2, 0, 'a')
worksheet.write(2, 1, 'b')
worksheet.write(2, 2, 'c')
worksheet.write(2, 3, 'd')
worksheet.write(2, 4, 'e')
# Cell안에 숫자값 입력하기2
# 좌표로 셀 안에 숫자값 입력하기(시작 index는 0부터)
worksheet.write(3, 0, 10)
worksheet.write(3, 1, 20)
worksheet.write(3, 2, 30)
worksheet.write(3, 3, 40)
worksheet.write(3, 4, 50)
# Workbook을 생성했으면 항상 닫아주기!
# 주의) 수정하고 싶으면 엑셀 파일 닫은 후 콜랩에서 수정
workbook.close()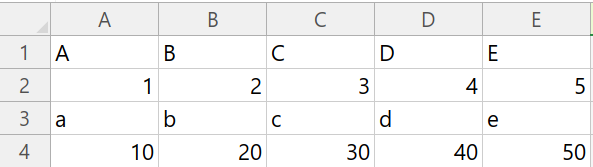
1.2 산술 연산 (사칙연산)
# 엑셀 파일 생성
workbook = xlsxwriter.Workbook('examplel1_2.xlsx')
# 엑셀 파일 안에 워크 시트 생성
worksheet = workbook.add_worksheet('leacoding')
# Cell안에 문자값 입력하기
worksheet.write('A1', 10)
worksheet.write('B1', 5)
#사칙연산
worksheet.write('A2', '=A1+B1')
worksheet.write('B2', '=A1-B1')
worksheet.write('C2', '=A1*B1')
worksheet.write('D2', '=A1/B1')
#사칙연산 함수 (결과값은 위와 같음)
worksheet.write('A3', '=SUM(A1,B1)') # 여러값 적을 수 있음 =SUM(A1,B1,C1)
worksheet.write('B3', '=IMSUB(A1,B1)')
worksheet.write('C3', '=PRODUCT(A1,B1)')
worksheet.write('D3', '=QUOTIENT(A1,B1)')
workbook.close()
1.3 비교 연산
# 엑셀 파일 생성
workbook = xlsxwriter.Workbook('examplel1_3.xlsx')
# 엑셀 파일 안에 워크 시트 생성
worksheet = workbook.add_worksheet('leacoding')
# Cell안에 문자값 입력하기
worksheet.write('A1', 10)
worksheet.write('B1', 5)
#사칙연산
worksheet.write('A2', '=A1=B1')
worksheet.write('B2', '=A1>B1')
worksheet.write('C2', '=A1>=B1')
worksheet.write('D2', '=A1<B1')
worksheet.write('E2', '=A1<=B1')
worksheet.write('F2', '=A1<>B1') # 다름
workbook.close()
1.4 기타 연산
# 엑셀 파일 생성
workbook = xlsxwriter.Workbook('examplel1_4.xlsx')
# 엑셀 파일 안에 워크 시트 생성
worksheet = workbook.add_worksheet('leacoding')
# Cell안에 문자값 입력하기
worksheet.write('A1', 10)
worksheet.write('B1', 20)
worksheet.write('C1', 30)
worksheet.write('D1', 40)
worksheet.write('E1', 50)
worksheet.write('F1', 60)
worksheet.write('G1', 'True') # 1
worksheet.write('H1', 'False')# 0
worksheet.write('I1', 'True')
worksheet.write('J1', 'False')
# Cell안에 문자값 입력하기
worksheet.write('A2', '=A1&B1') # 문자열 이어붙임 1020
worksheet.write('B2', '=SUM(A1:F1)') # 범위 지정해서 더하기(여기부터:여기까지) 210
worksheet.write('C2', '=SUM(A1,B1,C1,D1,E1,F1)') # 210
worksheet.write('D2', '=SUM(A1:C1, D1:E1)') # 범위지정 후 결합해서 더하기 150
worksheet.write('E2', '=A1^2') # 제곱 100
worksheet.write('F2', '=A1%') # 백분율 0.1
worksheet.write('G2', '=AND(G1,H1)') # AND는 곱 - FALSE
worksheet.write('H2', '=OR(G1,H1)') # OR는 합(둘 중에 하나라도 TRUE가 있으면 TRUE출력) - TRUE
worksheet.write('I2', '=OR(G1,I1)') # TRUE
worksheet.write('J2', '=OR(H1,J1)') # FALSE
workbook.close()
1.5 집계 함수
수식을 통해 집계 함수 활용 시 추후에 그래프를 그리거나 통계 낼 때 유리합니다.
참고 사이트
1. https://xlworks.net/
- 합계 : SUM()
- 최대값, 최소값 : MAX(), MIN()
- 평균 : AVERAGE()
- 중간(중앙)값 : 만약 데이터의 개수가 짝수일 경우 중앙 얖 옆의 값을 더하고 2로 나눈 값
- 1, 2, 4, 5, 1000, 100000의 경우 중간값은 (4+5)/2 = 4.5
- 개수
- COUNT() : Cell의 개수, 여기서 카운팅되는 값은 숫자와 날짜입니다. 문자나 공백, 논리값, 오류는 제외됩니다.
- COUNTA() : 비어있지 않은 셀의 개수를 구합니다.
- COUNTBLANK() : 비어있는 셀의 개수를 구합니다.
- COUNTIF() : 조건에 만족하는 셀의 개수를 구합니다.
- COUNTIFS() : 여러 조건에 ㅁ나족하는 셀의 개수를 구합니다.
- 분산 : VAR()
- 표준편차
- STDEV.P() : 모집단의 표준편차
- STDEV.S() : 표본집단의 표준편차
- 순위 : RANK()
# 엑셀 파일 생성
workbook = xlsxwriter.Workbook('examplel1_5.xlsx')
# 엑셀 파일 안에 워크 시트 생성
worksheet = workbook.add_worksheet('leacoding')
# 데이터 생성
score_data = [
['이름', '국', '영', '수'],
['서준', 100, 30, 55],
['서이', 91, 63, 88],
['서하', 50, 42, 100],
['서길', 83, 99, 75]
]
# 시작 지정
row = 0
col = 0
# for 변수명 in 범위
# f-string문법
for 이름, 국, 영, 수 in score_data:
worksheet.write(row, col, 이름)
worksheet.write(row, col+1, 국)
worksheet.write(row, col+2, 영)
worksheet.write(row, col+3, 수)
if row == 0:
worksheet.write(row, col+4, '점수합계')
worksheet.write(row, col+5, '최대값')
worksheet.write(row, col+6, '최소값')
worksheet.write(row, col+7, '평균')
worksheet.write(row, col+8, '순위')
else:
worksheet.write(row, col+4, f'{국+영+수}')
worksheet.write(row, col+5, f'{max(국,영,수)}')
worksheet.write(row, col+6, f'{min(국,영,수)}')
worksheet.write(row, col+7, f'{sum([국,영,수])/3}')
#worksheet.write(row, col+8, '=RANK(H2:H5)') # 평균을 기준으로 순위를 매길 것, 평균 col의 범위 지정
worksheet.write(row, col+8, '=RANK(H'+str(row+1)+',$H$2:$H$5,0)')
row += 1
# Cell안에 문자값 입력하기
worksheet.write('A1', 10)
worksheet.write('B1', 20)
workbook.close()
평균 칼럼에 들어있는 숫자를 ' 숫자로 변환'하면 순위가 정상적으로 보입니다.
write 메서드
지금까지 워크북을 만들거나 셀에 값을 입력하면서 xlsxwriter의 함수를 이용했습니다. Cell에 값을 입력하는 과정에서 쓰이는 것들은 Worksheet클래스에 있습니다. 그중 자주 쓰이게 될 만한 것을 정리해보겠습니다.
1) Worksheet.write(row, col, *args)
위와 같은 형식에 따라 매개변수를 받으면 *args의 형식에 따라 함수를 호출하여 처리합니다.
예) 문자열의 경우 write_string(), 숫자의 경우 write_number()
import xlsxwriter
# 엑셀 파일 생성
workbook = xlsxwriter.Workbook('examplel1_6_1.xlsx')
# 엑셀 파일 안에 워크 시트 생성
worksheet = workbook.add_worksheet('leacoding')
worksheet.write(0,0,'Excel') #문자열의 경우 - write_string()을 호출합니다
worksheet.write(1,0,3) #숫자의 경우 - write_number()을 호출합니다
worksheet.write(2,0,9.5) #숫자의 경우 - write_number()을 호출합니다
worksheet.write(3,0,'=COS(PI()/4)') # 공식의 경우 - write_formula()을 호출합니다
# worksheet.write_formula(3,0,'=COS(PI()/4)') 위와 결과 같음
worksheet.write(4,0,'') # 아무 값이 없을 경우 - write_blank()을 호출합니다
worksheet.write(5,0,None) # 아무 값이 없을 경우 - write_blank()을 호출합니다
workbook.close()
2) add_format()
일반적으로 write함수의 마지막 매개변수 자리에 넣어 여러 가지 기능을 설정할 수 있습니다.
예) 정렬, 폰트, 백그라운드 색
import xlsxwriter
# 엑셀 파일 생성
workbook = xlsxwriter.Workbook('examplel1_6_2.xlsx')
# 엑셀 파일 안에 워크 시트 생성
worksheet = workbook.add_worksheet('leacoding')
# 보고서 작성을 위해 키워드 지정
cellFormat = workbook.add_format({'bold':True, 'italic':True})
worksheet.write(0,0,'hello world', cellFormat)
workbook.close()
파일 입출력
일반 text파일(CSV)을 읽고 쓰기
파일 객체 = open('파일 이름', '파일 열기 모드')
파일 열기 모드는 r, w, a가 있습니다. r은 읽기 모드, w는 쓰기 모드이며 a는 파일의 마지막에 내용을 추가할 때 사용하는 모드입니다.
- CSV 파일이란 칼럼을 쉼표로 구분한 텍스트 파일입니다.
쓰기 모드
file =open('./example2.csv', 'w')
for i in range(10):
for j in range(5):
data = f'{i}{j}위치'
file.write(data)
data = f'\n'
file.write(data)
file.close()
읽기 모드
- readline()
- readlines()
- read()
file =open('/content/example2.csv', 'r')
data = file.readline()
print(data)
file.close()
// 출력
00위치01위치02위치03위치04위치
순회를 하면서 데이터를 전부 읽어올 수 있는 방법
file =open('/content/example2.csv', 'r')
while True:
data = file.readline()
print(data)
if not data:
break
file.close()
// 출력
00위치01위치02위치03위치04위치
10위치11위치12위치13위치14위치
20위치21위치22위치23위치24위치
30위치31위치32위치33위치34위치
40위치41위치42위치43위치44위치
50위치51위치52위치53위치54위치
60위치61위치62위치63위치64위치
70위치71위치72위치73위치74위치
80위치81위치82위치83위치84위치
90위치91위치92위치93위치94위치순회를 하지 않고도 한 번에 출력하는 방법 (리스트로 출력)
file =open('/content/example2.csv', 'r')
data = file.readlines()
print(data)
file.close()
// 출력
['00위치01위치02위치03위치04위치\n', '10위치11위치12위치13위치14위치\n', '20위치21위치22위치23위치24위치\n', '30위치31위치32위치33위치34위치\n', '40위치41위치42위치43위치44위치\n', '50위치51위치52위치53위치54위치\n', '60위치61위치62위치63위치64위치\n', '70위치71위치72위치73위치74위치\n', '80위치81위치82위치83위치84위치\n', '90위치91위치92위치93위치94위치\n']
텍스트 전체를 string값으로 가지고 오는 방법
file =open('/content/example2.csv', 'r')
data = file.read()
print(type(data))
print(data)
file.close()
// 출력
<class 'str'>
00위치01위치02위치03위치04위치
10위치11위치12위치13위치14위치
20위치21위치22위치23위치24위치
30위치31위치32위치33위치34위치
40위치41위치42위치43위치44위치
50위치51위치52위치53위치54위치
60위치61위치62위치63위치64위치
70위치71위치72위치73위치74위치
80위치81위치82위치83위치84위치
90위치91위치92위치93위치94위치
이외 유용한 기능들
csv 파일로 저장, 읽기
# csv 파일로 저장 (한글이 깨지는 경우가 있기 때문에 encoding 추가)
df.to_csv('pandas_c.csv', encoding = 'utf-8-sig')
# csv 파일 읽기
df_ = pd.read_csv('pandas_c.csv')
df_
concat : 데이터 프레임끼리 결합 (필요한 칼럼만 뽑아서 결합)
평가 = pd.concat([학점, 토익, 자격증, 교육, 컴퓨터언어능력], axis=1)
평가
칼럼 생성
평가['합계'] = 평가.sum(axis=1)
평가
오름차순, 내림차순 정렬
총합 = 평가['합계'].value_counts()
총합.sort_index(ascending=False)
label 생성
labels = ["1순위", "2순위", "3순위", "4순위"]
for i in range(len(총합)):
la = str(총합.index[i]) + "점"
labels.append(la)
labels
여기까지 기본적인 기능을 알아보았습니다. 기획팀에서 종종 엑셀 파일을 가공해서 출력해달라는 요청이 들어오는데요.
xlsxwriter 라이브러리를 익혀두신다면 이러한 요청이 들어왔을 때 빠르게 가공해서 드릴 수 있을 것 같습니다.
'Python' 카테고리의 다른 글
| 공공데이터와 Folium(폴리움)으로 제주 오름 지도 안내 서비스 만들기 (0) | 2022.10.28 |
|---|---|
| Python 내장 함수(Built-in Function) (0) | 2022.09.28 |
| Python 기본 문법 정리 (0) | 2022.09.28 |