2023. 3. 2. 17:05ㆍ기술 면접 준비
[기술면접] Spring - 2/3의 목차
- 롬복이 만드는 메소드들이 생성되는 시점
- 서블릿(Servlet)
- VO와 BO, DAO, DTO
- 대용량 트래픽에서 장애가 발생하면 어떻게 대응할 것인가요?
- Spring의 싱글톤 패턴
- Spring의 스코프 프로토 타입 빈
- @Transactional의 동작 원리
- JPA N + 1 문제와 발생하는 이유 그리고 해결하는 방법
- JPA와 같은 ORM을 사용하면서 쿼리가 복잡해지는 경우에는 어떻게 해결하는게 좋을까요?
[[ 간단 Q&A ]] - 스프링
- 스프링이랑 스프링 부트는 차이점
- MVC패턴
- MVC1이랑 MVC2 패턴 차이
- 스프링 MVC 구조 흐름에 대해 과정대로 설명해보세요.
- 스프링 필터랑 인터셉터의 차이점
- IOC란?
- Dispatcher-Servlet이란?
- DI(Dependency Injection)란?
- AOP(Aspect Oriented Programming)란?
- AOP 용어
- DAO(Data Access Object)란?
- Annotation이란?
- Spring JDBC란?
- MyBatis란?
😎 Lombok 라이브러리에 대해 알고 있나요? 알고 있다면 롬복이 만드는 메소드들이 생성되는 시점은 언제인가요?
Lombok은 메소드를 컴파일 하는 과정에 개입해서 추가적인 코드를 만들어냅니다. 이것을 어노테이션 프로세싱이라고 하는데, 어노테이션 프로세싱은 자바 컴파일러가 컴파일 단계에서 어노테이션을 분석하고 처리하는 기법을 말합니다.
(Lombok 라이브러리를 추가할 때 CompileOnly, AnnotationProcessor를 추가하는 이유도 된다.)
😎 서블릿(Servlet)에 대해 설명해주세요.
자바를 사용해 웹을 만들기 위해 필요한 기술입니다.
클라이언트의 요청을 처리하고, 그 결과를 반환하는 Servlet 클래스의 구현 규칙을 지킨 자바 웹 프로그래밍 기술입니다.
Spring MVC에서 Controller로 이용되며, 사용자의 요청을 받아 처리한 후에 결과를 반환합니다.
▶꼬리질문 - 서블릿의 동작방식에 대해 설명해주세요.
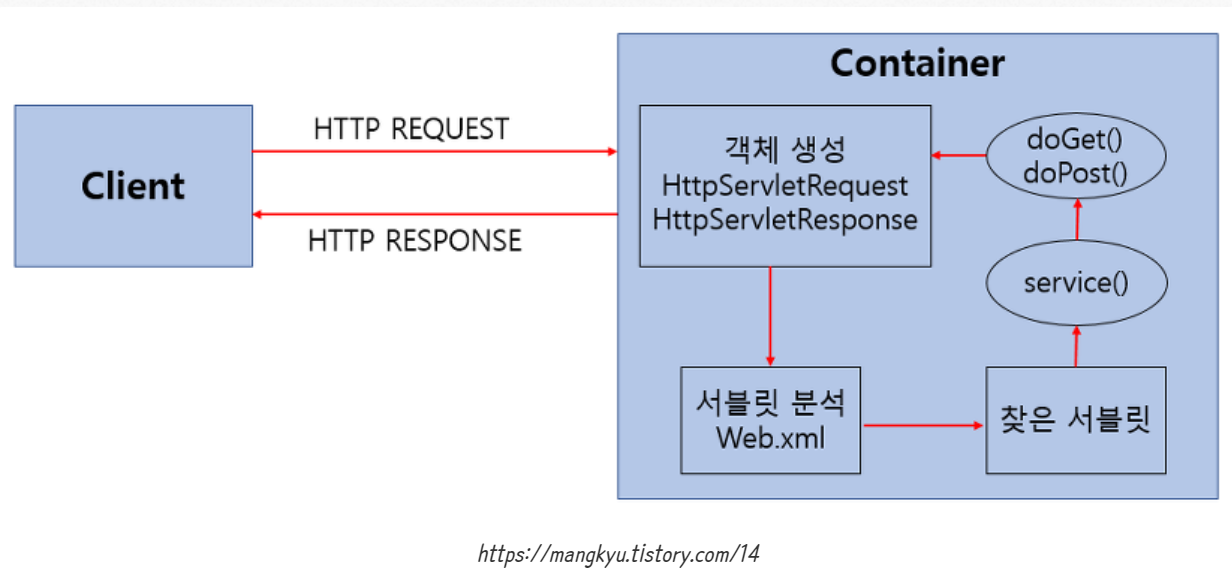
- 사용자(Client)가 URL을 입력하면 HTTP Request가 Servlet Container로 전송됩니다.
- 요청 받은 Servlet Container는 HttpServletRequest, HttpServletResponse 객체를 생성합니다.
- web.xml을 기반으로 사용자가 요청한 URL이 어느 서블릿에 대한 요청인지 찾습니다.
- 해당 서블릿에서 service메소드를 호출한 후 GET, POST여부에 따라 doGet() 또는 doPost()를 호출합니다.
- doGet() or doPost() 메소드는 동적 페이지를 생성한 후 HttpServletResponse객체에 응답을 보냅니다.
- 응답이 끝나면 HttpServletRequest, HttpServletResponse 두 객체를 소멸시킵니다.
😎 VO와 BO, DAO, DTO에 대해 설명해주세요.
- DAO(Data Access Object) DB의 데이터에 접근을 위한 객체를 말합니다. (Repository 또는 Mapper에 해당)
- BO(Business Object) 여러 DAO를 활용해 비즈니스 로직을 처리하는 객체를 말합니다. (Service에 해당)
- DTO(Data Transfer Object) 각 계층간의 데이터 교환을 위한 객체를 말합니다. (여기서 말하는 계층은 Controller, View, Business Layer, Persistent Layer)
- VO (Value Object) 실제 데이터만을 저장하는 객체를 말합니다.
▶ 꼬리질문 - DTO와 VO 그리고 Entity 차이점에 대해 말씀해주세요.
- Entity 란?
- Entity, DTO 클래스 분리하는 이유
- DTO 란?
- VO 란?
- DTO, VO 차이점
1. Entity 란?
Entity 클래스는 실제 DataBase의 테이블과 1 : 1로 매핑되는 클래스로,
DB의 테이블내에 존재하는 컬럼만을 속성(필드)으로 가져야 합니다.
Entity 클래스는 상속을 받거나 구현체여서는 안되며, 테이블내에 존재하지 않는 컬럼을 가져서도 안됩니다.
최대한 외부에서 Entity 클래스의 getter method를 사용하지 않도록 해당 클래스 안에서필요한 로직 method를 구현해야하고, Domain Logic만을 가지며, Presentation Logic을 가지고 있어서는 안됩니다.
2. Entity, DTO 클래스 분리하는 이유
Entity와 DTO를 분리해서 관리해야 하는 이유는 DB 와 View 사이의 역할을 철저히 분리하기 위해서 입니다.
Entity 클래스는 실제 테이블과 매핑되어 만일 변경되게 된다면 다른 클래스에 영향을 끼치고,
DTO 클래스는 View와 통신하며 자주 변경되므로 분리 해주어야 합니다. (Entity 클래스 보호)
DTO는 Domain Model의 순수성을 지키기 위해 DTO는 Domain Model 객체를 그대로 두고 복사하여
다양한 Presentation Logic을 추가한 정도로 사용합니다.
- DTO === copy(Domain Model) + Persentation Logic
3. DTO 란?
DTO(Data Transfer Object)
데이터 전송(이동) 객체라는 의미를 가지고 있습니다.
DTO는 주로 비동기 처리를 할 때 사용합니다.
DTO는 각 계층(Layer)간 데이터 교환을 위한 객체(Java Beans)입니다.
(ex. View <-(DTO) -> Controller <- (DTO) -> Service )
로직을 갖고 있지 않는 순수한 데이터 객체이며, getter/setter 메소드만을 갖습니다.
public class PersonDTO {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
위의 클래스를 보면 getter/setter 가 존재합니다.
여기서 중요한건 Property(프로퍼티) 개념인데, 자바는 Property가 문법적으로 제공되지 않습니다.
자바에서 프로퍼티라는 개념을 사용하기 위해 지켜야 할 약속이 있습니다.
setter/getter 에서 set과 get 이후에 나오는 단어가 property라고 약속하는 것입니다.
그래서 위 클래스에서 프로퍼티는 name과 age 입니다.
중요한 것은 프로퍼티가 멤버변수 name, age로 결정되는 것이 아닌 getter/setter에서의 name과 age임을 명심해야 합니다. 즉 멤버변수는 아무렇게 지어도 영향이 없고 getter/setter 로 프로퍼티(데이터)를 표현한다는 것입니다.
자바는 다양한 프레임워크에서 데이터 자동화처리를 위해 리플렉션 기법을 사용하는데,
데이터 자동화 처리에서 제일 중요한 것은 표준규격입니다.
예를들어 윗 클래스 DTO에서 property가 name, age라면 name, age의 키값으로 들어온 데이터는
리플렉션 기법으로 setter를 실행시켜 데이터를 넣을 수 있습니다.
중요한 것은, 우리가 setter를 요청하는 것이 아닌 프레임워크 내부에서 setter가 실행된다는 점입니다.(눈에 보이지않음)
그래서 layer간(특히 서버 -> View로 이동 등)에 데이터를 넘길때에는 DTO를 쓰면 편하다는 것이 이런이유 때문입니다.
View에 있는 form에서 name 필드 값을 프로퍼티에 맞춰 넘겼을 때, 받아야 하는 곳에서는 일일히 처리하는 것이 아니라
name속성의 이름이랑 매칭되는 프로퍼티에 자동적으로 DTO가 인스턴스화 되어 PersonDTO를 자료형으로 값을 받을 수 있습니다.
그래서 key-value 로 존재하는 데이터는 자동화 처리된 DTO로 변환되어 쉽게 데이터가 셋팅된 오브젝트를 받을 수 있습니다.
4.VO (Value Object)
VO(Value Object)는 말 그대로 값 오브젝트로써 값을 위해 쓰입니다.
VO는 변하지 않는 데이터 객체를 의미합니다.
오직 read만 가능하며 getter만 가능해야 합니다.
VO는 DTO와 차별화되는 점
객체의 불변성(객체의 정보가 변경되지 않음)을 보장합니다.
즉, 값을 설정한 뒤에는 수정할 수 없습니다.(Setter (X))
VO는 그럼 어떤 경우에 사용해야 할까?
데이터가 불변이어야 하고, 단순히 저장된 값을 불러와야 하는 경우
(ex. 서울의 지역번호는 누구나 다 알듯 02입니다. 그리고 핸드폰 번호처럼 변하는 게 아닌 고정된 값입니다.
그렇기 때문에 위와 같이 고정된 값은 VO로 저장 후 Getter 호출 합니다.)
5. DTO와 VO의 차이점
DTO는 데이터의 전송만을 위한 객체이고, VO는 특정한 비즈니스 로직을 가질 수 있습니다.
DTO는 데이터 전달만을 목적으로 하고, VO는 객체 자체를 어떠한 값(Value)으로서 사용합니다.
(외부 시스템과 데이터 통신을 할 경우 DTO로, DB에서 가져오는 Data는 VO로 정의 후 사용)
DTO는 목적 자체가 데이터의 전달이므로, 읽고 쓰는 것이 모두 가능해 가변성을 갖고,
VO는 불변성 및 read-only의 속성을 갖습니다.
VO는 equals()와 hashCode()를 재정의(Override) 해서 각 객체의 동일성을 판별할 수 있습니다.
간단하게
DTO a = new DTO(1);
DTO b = new DTO(1);
라고 했을때 a != b 이지만,
VO a = new VO(1);
VO b = new VO(1);
라고 했을때 a==b 입니다.
😎 대용량 트래픽에서 장애가 발생하면 어떻게 대응할 것인가요?
스케일 업을 통해 하드웨어 스펙을 향상 / 스케일 아웃을 통해 서버를 여러대 추가해 시스템을 증가시키면됩니다.
▶꼬리질문 - 스케일 업, 스케일 아웃이란?
스케일 업과 스케일 아웃은 인프라 확장을 위한 두 가지 방법이다.
서버를 운영하다 보면 이용자가 증가하거나 사업을 확장 할 때 많은 서버 용량과 성능이 필요하게 되는데,
'스케일 업'과 '스케일 아웃'으로 인프라 확장 문제를 해결할 수 있다.
스케일 업(Scale-Up)
스케일 업은 기존 서버의 사양을 업그레이드해 시스템을 확장하는 것을 말한다.
CPU나 RAM 등을 추가하거나 고성능의 부품, 서버로 교환하는 방법이다.
이처럼 하나의 서버의 사양을 업그레이드 하기 때문에 수직 스케일로 불리기도 한다.
스케일 아웃(Scale-Out)
스케일 아웃은 서버를 여러 대 추가하여 시스템을 확장하는 것을 말한다.
서버가 여러 대로 나뉘기 때문에 각 서버에 걸리는 부하를 균등하게 해주는 '로드밸런싱'이 필수적으로 동반되어야 한다.
이처럼 여러 대의 서버로 나눠 시스템을 확장하기 때문에 수평 스케일로 불리기도 한다.

😎 Spring의 싱글톤 패턴에 대해 설명해주세요.
스프링에서 bean 생성시 별다른 설정이 없으면 default로 싱글톤이 적용됩니다.
스프링은 컨테이너를 통해 직접 싱글톤 객체를 생성하고 관리하는데,
요청이 들어올 때마다 매번 객체를 생성하지 않고, 이미 만들어진 객체를 공유하기 때문에 효율적인 사용이 가능합니다.
Java로 기본적인 싱글톤 패턴을 구현하고자 하면 다음과 같은 단점들이 발생한다.
- private 생성자를 갖고 있어 상속이 불가능하다.
- 테스트하기 힘들다.
- 서버 환경에서는 싱글톤이 1개만 생성됨을 보장하지 못한다.
- 전역 상태를 만들 수 있기 때문에 바람직하지 못하다.
그래서 스프링은 컨테이너를 통해 직접 싱글톤 객체를 생성하고 관리하는데, 이를 통해 다음과 같은 장점을 얻을 수 있다.
- static 메소드나 private 생성자 등을 사용하지 않아 객체지향적 개발을 할 수 있다.
- 테스트를 하기 편리하다.
😎 Spring의 스코프 프로토 타입 빈에 대해 설명해주세요.
프로토타입 빈은 싱글톤(default bean) 빈과는 달리 컨테이너에게 빈을 요청할 때마다 매번 새로운 객체를 생성하여 반환해줍니다.
빈의 scope 설정은 @Scope 어노테이션으로 설정하며, 프로토타입 scope로 설정하려면 @Scope(”prototype”)와 같이 문자열로 지정해줍니다.
😎 @Transactional의 동작 원리에 대해 설명해주세요.
@Transactional을 메소드 또는 클래스에 명시하면, AOP를 통해 Target이 상속하고 있는 인터페이스 또는 Target 객체를 상속한 Proxy 객체가 생성되며, Proxy 객체의 메소드를 호출하면 Target 메소드 전 후로 트랜잭션 처리를 수행합니다.
▶ 꼬리질문 - @Transactional를 스프링 Bean의 메소드 A에 적용하였고, 해당 Bean의 메소드 B가 호출되었을 때, B 메소드 내부에서 A 메소드를 호출하면 어떤 요청 흐름이 발생하는지 설명해주세요.
프록시는 클라이언트가 타겟 객체를 호출하는 과정에만 동작하며, 타겟 객체의 메소드가 자기 자신의 다른 메소드를 호출할 때는 프록시가 동작하지 않습니다.
즉, A 메소드는 프록시로 감싸진 메소드가 아니므로 트랜잭션이 적용되지 않은 일반 코드가 수행됩니다.
▶ 꼬리질문 - @Transactional에 readOnly 속성을 사용하는 이유에 대해서 설명해주세요.
트랜잭션 안에서 수정/삭제 작업이 아닌 ReadOnly 목적인 경우에 주로 사용하며,
영속성 컨텍스트에서 엔티티를 관리 할 필요가 없기 때문에 readOnly를 추가하는 것으로 메모리 성능을 높일 수 있고,
데이터 변경 불가능 로직임을 코드로 표시할 수 있어 가독성이 높아진다는 장점이 있습니다.
readOnly 속성이 없는 보통의 트랜잭션은 데이터 조회 결과 엔티티가 영속성 컨텍스트에 관리되며,
이는 1차 캐싱부터 변경 감지(Dirty Checking)까지 가능하게 된다.
하지만, 조회시 스냅샷 인스턴스를 생성해 보관하기 때문에 메모리 사용량이 증가한다.
😎 JPA N + 1 문제와 발생하는 이유 그리고 해결하는 방법을 설명해주세요.
N+1이란 1번의 쿼리를 날렸을 때 의도하지 않은 N번의 쿼리가 추가적으로 실행되는 것을 의미합니다.
해결 방법에는 여러 방법이 있지만 가장 많이 사용되는 방법은 Fetch Join을 사용해 해결하는 방법입니다.
N+1 문제가 발생하는 이유는 연관관계를 가진 엔티티를 조회할 때 한 쪽 테이블만 조회하고 연결된 다른 테이블은 따로 조회하기 때문인데,
Fetch Join을 사용하면 미리 두 테이블을 Join하여 한 번에 모든 데이터를 가져오기 때문에 N+1문제를 애초에 막을 수 있습니다.
▶꼬리질문 - [JPA] N+1 문제 원인 및 해결방법 알아보기
JPA를 사용하면 자주 만나게 되는 것이 N + 1 문제이다.
N + 1 문제는 성능에 큰 영향을 줄 수 있기 때문에 N + 1 문제가 무엇이고 어떤 상황에 발생되는지,
어떻게 해결하면 되는지에 대해 알아보고자 한다.
- JPA N+1 문제란
- 코드 예시
- N+1 문제 해결 방법
1. JPA N+1 문제란
N + 1문제란 1번의 쿼리를 날렸을 때 의도하지 않은 N번의 쿼리가 추가적으로 실행되는 것을 의미한다.
When 언제 발생하는가?
- JPA Repository를 활용해 인터페이스 메소드를 호출할 때(Read 시)
Who 누가 발생시키는가?
- 1:N 또는 N:1 관계를 가진 엔티티를 조회할 때 발생
How 어떤 상황에 발생되는가?
- JPA Fetch 전략이 EAGER 전략으로 데이터를 조회하는 경우
- JPA Fetch 전략이 LAZY 전략으로 데이터를 가져온 이후에 연관 관계인 하위 엔티티를 다시 조회하는 경우
Why 왜 발생하는가?
- JPA Repository로 find 시 실행하는 첫 쿼리에서 하위 엔티티까지 한 번에 가져오지 않고, 하위 엔티티를 사용할 때 추가로 조회하기 때문에.
- JPQL은 기본적으로 글로벌 Fetch 전략을 무시하고 JPQL만 가지고 SQL을 생성하기 때문에.
EAGER(즉시 로딩)인 경우
1. JPQL에서 만든 SQL을 통해 데이터를 조회
2. 이후 JPA에서 Fetch 전략을 가지고 해당 데이터의 연관 관계인 하위 엔티티들을 추가 조회
3. 2번 과정으로 N + 1 문제 발생
LAZY(지연 로딩)인 경우
1. JPQL에서 만든 SQL을 통해 데이터를 조회
2. JPA에서 Fetch 전략을 가지지만, 지연 로딩이기 때문에 추가 조회는 하지 않음
3. 하지만, 하위 엔티티를 가지고 작업하게 되면 추가 조회가 발생하기 때문에 결국 N + 1 문제 발생
2. 코드 예시
사람과 애완동물의 관계를 표현해보겠다.
- 주인은 여러 마리의 애완동물을 키우고 있다.
- 애완동물은 한 명의 주인에 종속되어 있다.
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Getter
@Setter
@Entity
public class Owner {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "owner", fetch = FetchType.EAGER)
private List<Pet> pets = new ArrayList<>();
}
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Getter
@Entity
public class Pet {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne
private Owner owner;
}
이제 테스트 코드를 작성하고 조회해보자
@Test
void test() {
List<Pet> pets = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Pet pet = Pet.builder().name("pet" + i).build();
pets.add(pet);
}
petRepository.saveAll(pets);
List<Owner> owners = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Owner owner = Owner.builder().name("owner" + i).build();
owner.setPets(pets);
owners.add(owner);
}
ownerRepository.saveAll(owners);
System.out.println("-------------------------------");
List<Owner> ownerList = ownerRepository.findAll();
}Hibernate SQL Log를 활성화하고 실제로 호출된 쿼리를 확인해 보자.
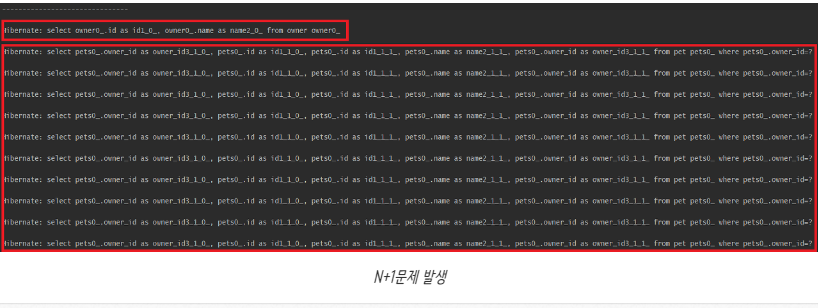
3. N+1 문제 해결 방법
해결 방법에는 여러 방법들이 있지만 FetchJoin과 EntityGraph 두 가지 방법을 알아보도록 하겠다.
1. Fetch Join(패치 조인)
N+1 자체가 발생하는 이유는 한쪽 테이블만 조회하고 연결된 다른 테이블은 따로 조회하기 때문이다.
미리 두 테이블을 JOIN 하여 한 번에 모든 데이터를 가져올 수 있다면 애초에 N+1 문제가 발생하지 않을 것이다.
그렇게 나온 해결 방법이 FetchJoin 방법이다.
두 테이블을 JOIN 하는 쿼리를 직접 작성하는 것이다.
다음과 같이 JPQL을 직접 지정해준다.
@Query("select DISTINCT o from Owner o join fetch o.pets")
List<Owner> findAllJoinFetch();
@Test
void test() {
...
System.out.println("-------------------------------");
List<Owner> ownerList = ownerRepository.findAllJoinFetch();
}결과를 보면 쿼리가 1번만 발생하고 미리 owner와 pet 데이터를 조인(Inner Join)해서 가져오는 것을 볼 수 있다.
Fetch Join(패치 조인)의 단점
- 쿼리 한번에 모든 데이터를 가져오기 때문에 JPA가 제공하는 Paging API 사용 불가능(Pageable 사용 불가)
- 1:N 관계가 두 개 이상인 경우 사용 불가
- 패치 조인 대상에게 별칭(as) 부여 불가능
- 번거롭게 쿼리문을 작성해야 함
2. @Entity Graph
@EntityGraph 의 attributePaths는 같이 조회할 연관 엔티티명을 적으면 된다. ,(콤마)를 통해 여러 개를 줄 수도 있다.
Fetch join과 동일하게 JPQL을 사용해 Query문을 작성하고 필요한 연관관계를 EntityGraph에 설정하면 된다.
@EntityGraph(attributePaths = {"pets"})
@Query("select DISTINCT o from Owner o")
List<Owner> findAllEntityGraph();
@Test
void test() {
...
System.out.println("-------------------------------");
List<Owner> ownerList = ownerRepository.findAllEntityGraph();
}결과를 보면 쿼리가 1번만 발생하고 미리 owner와 pet 데이터를 조인(outerJoin)해서 가져오는 것을 볼 수 있다.
Fetch Join과 @EntityGraph의 출력되는 쿼리를 보면 알다시피
Fetch join의 경우 inner join을 하는 반면에 EntityGraph는 outer join을 기본으로 한다.
(기본적으로 outer join 보다 inner join이 성능 최적화에 더 유리하다.)
4. Fetch Join과 EntityGraph 사용시 주의할 점
FetchJoin과 EntityGraph는 공통적으로 카테시안 곱(Cartesian Product)이 발생 하여 중복이 생길 수 있다.
※ 카테시안 곱 : 두 테이블 사이에 유효 join 조건을 적지 않았을 때 해당 테이블에 대한 모든 데이터를 전부 결합하여 테이블에 존재하는 행 갯수를 곱한만큼의 결과 값이 반환되는 것
이런 중복 발생 문제를 해결하기 위한 방법은 다음과 같다.
1. JPQL에 DISTINCT 를 추가하여 중복 제거
@Query("select DISTINCT o from Owner o join fetch o.pets")
List<Owner> findAllJoinFetch();
@EntityGraph(attributePaths = {"pets"})
@Query("select DISTINCT o from Owner o")
List<Owner> findAllEntityGraph();
2. OneToMany 필드 타입을 Set으로 선언하여 중복 제거
@OneToMany(mappedBy = "owner", fetch = FetchType.EAGER)
private Set<Pet> pets = new LinkedHashSet<>();(Set은 순서가 보장되지 않는 특징이 있지만, 순서 보장이 필요한 경우 LinkedHashSet을 사용하자.)
카테시안 곱(Cartesian Product) 피하기
카테시안 곱이 일어나는 Cross Join은 JPA 기능 때문이 아니라, 쿼리의 표현에서 발생하는 문제이다.
Cross Join이 일어나는 조건은 간단하다.
Join 명령을 했을 때 명확한 Join 규칙이 주어지지 않았을 때,
* join 이후 on 절이 없을 때, db는 두 테이블의 결합한 결과는 내보내야겠고, 조건이 없으니 M * N으로 모든 경우의 수를 출력하는 것이다.
JPA는 사용자가 보내준 코드를 해석해서 최적의 sql 문장을 조립하는데,
이 때 코드가 얼마나 연관관계를 명확히 드러냈냐에 따라 발생 할 수도 안 할 수도 있다.
Fetch Join과 @EntityGraph의 기능은 'Cross Join을 만들어라' 나 'Inner Join을 만들어라' 가 아니고,
'연관관계 데이터를 미리(EAGER) 함께 가져와라' 이다.
JPA 프레임워크로부터 특정한 방향(흔히 inner join)으로 최적화된 쿼리를 유도하려면,
프레임워크가 이해할 수 있는 연관관계와 상황을 코드로 적절히 전달하면 된다.
이 때 Fetch Join, FetchType.EAGER, @EntityGraph, Querydsl 등이 최적화된 쿼리를 유도하는 데 도움을 주는 것이다.
😎 JPA와 같은 ORM을 사용하면서 쿼리가 복잡해지는 경우에는 어떻게 해결하는게 좋을까요?
일단 JPA 자체는 정적인 상황에서 사용하는걸 권장하기 때문에 복잡한 쿼리와 동적인 쿼리에 대한 문제가 발생하게 되는데, 그럴때는 JPQL과 Querydsl을 사용할 것을 권장하고 있습니다.
스프링이 뭔지 간단히 설명해보세요
스프링은 자바 플랫폼을 위한 오픈소스 애플리케이션 프레임워크입니다. 자바 SE로 된 자바 객체 POJO를 자바 EE에 의존적이지 않게 연결해주는 역할을 합니다. 스프링의 특징으로는 크기와 부하 측면에서 경량 시킨 것과, IOC 기술로 애플리케이션의 느슨한 결합을 도모시킨 것이 있습니다.
* POJO란?
가장 기본적인 형태의 Java 객체를 POJO라 합니다.
진정한 POJO란 객체지향적인 원리에 충실하면서, 환경과 기술에 종속되지 않고
필요에 따라 재활용될 수 있는 방식으로 설계된 오브젝트를 말한다.
스프링이랑 스프링 부트는 차이점이 뭔가요?
스프링 부트는 스프링에서 사용하는 프로젝트를 간편하게 셋업할 수 있는 서브 프로젝트입니다. 독립 컨테이너에서 동작할 수 있기 때문에 임베디드 톰켓이 자동으로 실행되구요. 임베디드 컨테이너에서 애플리케이션을 실행시키기에는 다소 불안전해서 큰 프로젝트는 사용하지 않는 것이 좋습니다.
MVC패턴이란?
MVC 패턴은 코드의 재사용에 유용하며, 사용자 인터페이스와 응용 프로그램 개발에 소요되는 시간을 줄여주는 효과적인 설계 방식을 말합니다.
구성요소로는 Model, View, Controller가 있는데요. 모델은 핵심적인 비즈니스 로직을 담당하여 데이터베이스를 관리하는 부분이고, 뷰는 사용자에게 보여주는 화면, 컨트롤러는 모델과 뷰 사이에서 정보 교환을 할 수 있도록 연결시켜주는 역할을 합니다.
MVC1이랑 MVC2 패턴 차이에 대해 설명해주세요.
모델1은 JSP페이지 안에서 로직 처리를 위해 자바 코드가 함께 사용됩니다. 요청이 오면, 직접 자바빈이나 클래스를 이용해 작업을 처리하고, 이를 클라이언트에 출력해줍니다. 구조가 단순한 장점이 있지만, JSP 내에서 html 코드와 자바 코드가 같이 사용되면서 복잡해지고 유지보수가 어려운 단점이 있습니다.
모델2는 이와는 다르게 모든 처리를 JSP에서만 담당하는 것이 아니라 서블릿을 만들어 역할 분담을 하는 패턴입니다. 요청 결과를 출력해주는 뷰만 JSP가 담당하고, 흐름을 제어해주고 비즈니스 로직에 해당하는 컨트롤러의 역할을 서블릿이 담당하게 됩니다. 이처럼 역할을 분담하면서 유지보수가 용이해지는 장점이 있지만 습득하기 힘들고 구조가 복잡해지는 단점도 있습니다.
스프링 MVC 구조 흐름에 대해 과정대로 설명해보세요.
우선, 디스패처 서블릿이 클라이언트로부터 요청을 받으면, 이를 요청할 핸들러 이름을 알기 위해 핸들러맵핑에게 물어봅니다.
핸들러맵핑은 요청 url을 보고 핸들러 이름을 디스패처 서블릿에게 알려줍니다. 이때 핸들러를 실행하기 전/후에 처리할 것들을 인터셉터로 만들어 줍니다.
디스패처 서블릿은 해당 핸들러에게 제어권을 넘겨주고, 이 핸들러는 응답에 필요한 서비스를 호출하고 렌더링해야 하는 뷰 이름을 판단하여 디스패처 서블릿에게 전송해줍니다.
디스패처 서블릿은 받은 뷰 이름을 뷰 리졸버에게 전달해 응답에 필요한 뷰를 만들라고 명령합니다.
이때 해당하는 뷰는 디스패처 서블릿에게 받은 모델과 컨트롤러를 활용해 원하는 응답을 생성해서 다시 보내줍니다.
디스패처 서블릿은 뷰로부터 받은 것을 클라이언트에게 응답해줍니다.
스프링 필터랑 인터셉터의 차이점은 뭔가요?
필터와 인터셉터는 실행되는 시점에서 차이가 있습니다. 필터는 웹 애플리케이션에 등록을 하고, 인터셉터는 스프링의 context에 등록을 합니다. 따라서 컨트롤러에 들어가기 전 작업을 처리하기 위해 사용하는 공통점이 있지만, 호출되는 시점에서 차이가 존재합니다.
IOC란?
IOC란, 인스턴스의 생성부터 소멸까지 개발자가 아닌 컨테이너가 대신 관리해주는 것을 말합니다. 인스턴스 생성의 제어를 서블릿과 같은 bean을 관리해주는 컨테이너가 관리합니다.
Dispatcher-Servlet이란?
서블릿 컨테이너에서 HTTP 프로토콜을 통해 들어오는 모든 요청을 제일 앞에서 처리해주는 프론트 컨트롤러를 말합니다.
따라서 서버가 받기 전에, 공통처리 작업을 디스패처 서블릿이 처리해주고 적절한 세부 컨트롤러로 작업을 위임해줍니다.
디스패처 서블릿이 처리하는 url 패턴을 지정해줘야 하는데, 일반적으로는 MVC와 같은 패턴으로 처리하라고 미리 지정해줍니다.
디스패처 서블릿으로 인해 web.xml이 가진 역할이 상당히 축소되었습니다. 기존에는 모든 서블릿을 url 매핑 활용을 위해 모두 web.xml에 등록해 주었지만, 디스패처 서블릿은 그 전에 모든 요청을 핸들링해주면서 작업을 편리하게 할 수 있도록 도와줍니다. 또한 이 서블릿을 통해 MVC를 사용할 수 있기 때문에 웹 개발 시 큰 장점을 가져다 줍니다.
DI(Dependency Injection)란?
스프링 컨테이너가 지원하는 핵심 개념 중 하나로, 설정 파일을 통해 객체간의 의존관계를 설정하는 역할을 합니다.
각 클래스 사이에 필요로 하는 의존관계를 Bean 설정 정보 바탕으로 컨테이너가 자동으로 연결합니다.
객체는 직접 의존하고 있는 객체를 생성하거나 검색할 필요가 없으므로 코드 관리가 쉬워지는 장점이 있습니다.
AOP(Aspect Oriented Programming)란?
공통의 관심 사항을 적용해서 발생하는 의존 관계의 복잡성과 코드 중복을 해소해줍니다.
각 클래스에서 공통 관심 사항을 구현한 모듈에 대한 의존관계를 갖기 보단, Aspect를 이용해 핵심 로직을 구현한 각 클래스에 공통 기능을 적용합니다.
간단한 설정만으로도 공통 기능을 여러 클래스에 적용할 수 있는 장점이 있으며 핵심 로직 코드를 수정하지 않고도 웹 애플리케이션의 보안, 로깅, 트랜잭션과 같은 공통 관심 사항을 AOP를 이용해 간단하게 적용할 수 있습니다.
AOP 용어들을 설명해보세요
Advice : 언제 공통 관심기능을 핵심 로직에 적용할지 정의
Joinpoint : Advice를 적용이 가능한 지점을 의미 (before, after 등등)
Pointcut : Joinpoint의 부분집합으로, 실제로 Advice가 적용되는 Joinpoint를 나타냄
Weaving : Advice를 핵심 로직코드에 적용하는 것
Aspect : 여러 객체에 공통으로 적용되는 공통 관심 사항을 말함. 트랜잭션이나 보안 등이 Aspect의 좋은 예
DAO(Data Access Object)란?
DB에 데이터를 조회하거나 조작하는 기능들을 전담합니다.
Mybatis를 이용할 때는, mapper.xml에 쿼리문을 작성하고 이를 mapper 클래스에서 받아와 DAO에게 넘겨주는 식으로 구현합니다.
Annotation이란?
소스코드에 @어노테이션의 형태로 표현하며 클래스, 필드, 메소드의 선언부에 적용할 수 있는 특정기능이 부여된 표현법을 말합니다.
애플리케이션 규모가 커질수록, xml 환경설정이 매우 복잡해지는데 이러한 어려움을 개선시키기 위해 자바 파일에 어노테이션을 적용해서 개발자가 설정 파일 작업을 할 때 발생시키는 오류를 최소화해주는 역할을 합니다.
어노테이션 사용으로 소스 코드에 메타데이터를 보관할 수 있고, 컴파일 타임의 체크뿐 아니라 어노테이션 API를 사용해 코드 가독성도 높여줍니다.
- @Controller : dispatcher-servlet.xml에서 bean 태그로 정의하는 것과 같음.
- @RequestMapping : 특정 메소드에서 요청되는 URL과 매칭시키는 어노테이션
- @Autowired : 자동으로 의존성 주입하기 위한 어노테이션
- @Service : 비즈니스 로직 처리하는 서비스 클래스에 등록
- @Repository : DAO에 등록
Spring JDBC란?
데이터베이스 테이블과, 자바 객체 사이의 단순한 매핑을 간단한 설정을 통해 처리하는 것
기존의 JDBC에서는 구현하고 싶은 로직마다 필요한 SQL문이 모두 달랐고, 이에 필요한 Connection, PrepareStatement, ResultSet 등을 생성하고 Exception 처리도 모두 해야하는 번거러움이 존재했습니다.
Spring에서는 JDBC와 ORM 프레임워크를 직접 지원하기 때문에 따로 작성하지 않아도 모두 다 처리해주는 장점이 있습니다.
MyBatis란?
객체, 데이터베이스, Mapper 자체를 독립적으로 작성하고, DTO에 해당하는 부분과 SQL 실행결과를 매핑해서 사용할 수 있도록 지원함
기존에는 DAO에 모두 SQL문이 자바 소스상에 위치했으나, MyBatis를 통해 SQL은 XML 설정 파일로 관리합니다.
설정파일로 분리하면, 수정할 때 설정파일만 건드리면 되므로 유지보수에 매우 좋습니다. 또한 매개변수나 리턴 타입으로 매핑되는 모든 DTO에 관련된 부분도 모두 설정파일에서 작업할 수 있는 장점이 있습니다.
관련 포스팅
[기술면접] Spring - 1/3
[기술면접] Spring - 2/3
[기술면접] Spring - 3/3
출처:
https://mangkyu.tistory.com/95
https://dev-coco.tistory.com/163
https://gyoogle.dev/blog/
'기술 면접 준비' 카테고리의 다른 글
| [기술면접] JAVA - 1/4 (0) | 2023.03.02 |
|---|---|
| [기술면접] Spring - 3/3 (0) | 2023.03.02 |
| [기술면접] Spring - 1/3 (0) | 2023.03.02 |
| [기술면접] 프로그래밍 공통 (0) | 2023.03.02 |
| [자료구조] 시간복잡도 (1) | 2022.11.21 |