2023. 6. 2. 17:26ㆍCS/Network
1편 인터넷 네트워크 편에 이어 2편도 이어서 작성해 보도록 하겠습니다.
목차
인터넷 네트워크
URI와 웹 브라우저 요청 흐름
HTTP 기본(특징, 메서드, 상태코드)
HTTP 헤더
HTTP 캐시
URI(Uniform Resource Identifier)
리소스를 식별하는 통합된 방법입니다.
프로그래밍을 학습하다 보면 URL, URI가 등장합니다. 저는 처음에 URI가 오타인 줄 알고 선생님께 여쭤본 기억이 있는데요. 둘은 어떤 차이점이 있을까요?
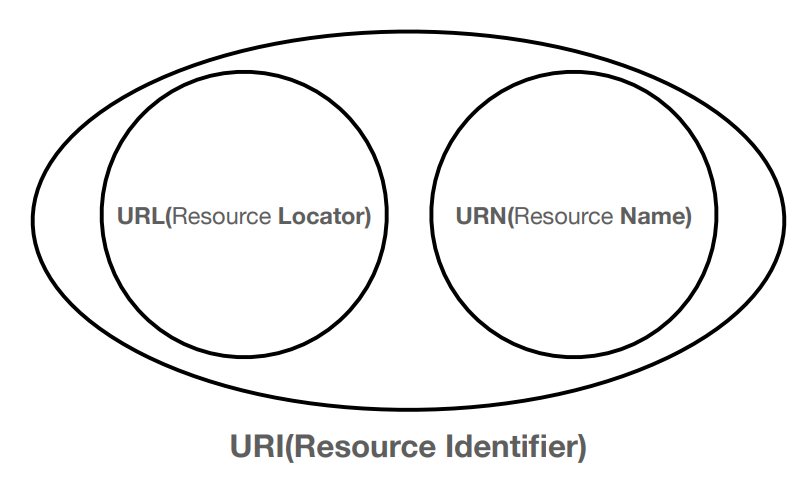
URI는 URL과 다른 개념이 아닌 URL을 포함하는 개념이라는 것을 알 수 있습니다.
URL은 리소스의 위치를 나타내고,
URN은 리소스의 이름을 나타냅니다.
리소스의 이름만으로는 실제 리소스를 찾을 수 없으므로 URL을 사용하기에 URI는 URL과 같은 의미로 이야기하기도 합니다.
[참고] 리소스 위치는 변할 수 있지만 이름은 변하지 않습니다.
URI
Uniform: 리소스를 식별하는 통일된 방식
Resource: 자원, URI로 식별가능한 모든 것
Identifier: 다른 항목과 구분되는 정보 예)주민번호
이번에는 URL 문법을 분석해보겠습니다.
https://www.google.com:443/search?q=개발자
⬇
scheme://[userinfo@]host[:port][/path][?query][#fragment]
scheme
주로 프로토콜이 사용됩니다. 프로토콜은 어떤 방식으로 자원에 접근할 것인가 하는 클라이언트와 서버 간의 규칙입니다. 예를 들어 http, https, ftp 등이 있습니다. 주로 http는 80 포트, https는 443 포트를 주로 사용합니다.
host
도메인명 또는 IP 주소입니다.
path
리소스 경로로 계층적 구조로 나타냅니다.
예) /student/number/3
query = query parameter = query string
key=value형태로 ?로 시작합니다. 추가적인 내용은 &를 넣어 작성합니다.
예) ?keyA=valueA&keyB=valueB....
여기까지 간단하게 URL에 대해 살펴보았습니다. 이번에는 단골 질문이기도 한
"URL 호출 시 실제 웹 브라우저는 어떤 식으로 동작해서 브라우저에 렌더링 되는 것일까요?"
웹 브라우저 요청 흐름
1. URL호출 시, DNS서버를 조회해서 IP와 PORT정보를 찾아냅니다.
2. HTTP 요청 메시지를 생성합니다.
GET /search?q=hello=ko HTTP/1.1
Host: www.google.com
3. HTTP 메시지 전송합니다.
웹 브라우저가 HTTP메시지를 생성 ➡
SOCKET라이브러리를 통해 OS의 TCP/IP계층에 TCP 3 way handshake로 전달➡...
인터넷으로 전달
4. 요청 패킷이 서버에 도착하면 패킷 안에 있는 HTTP메시지를 꺼내어 해석 후 데이터를 찾습니다.
그 후 HTTP응답 메시지를 생성합니다.
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Length: 3423
<html>
<body>... <body>
</html>
이제 클라이언트로 보내줘야겠죠,
5. 서버 또한 응답 패킷을 전달하게 됩니다.
* 응답 패킷: HTTP메시지를 TCP/IP패킷으로 감싼 형태
6. HTTP메시지를 받아서, 웹 브라우저에 HTML렌더링을 하게 됩니다.
간단하게 웹 브라우저 요청 흐름에 대해 알아보았습니다. 중간중간 HTTP 개념이 나왔는데 본격적으로 HTTP가 무엇인지 어떤 특징이 있는지 알아본 후 다음 포스팅에 이어 중요한 특징들을 학습해 보겠습니다.
HTTP (HyperText Transfer Protocol)
처음에는 HTML문서를 링크로 전송하는 프로토콜로 시작하였으나, 지금은 모든 것을 HTTP메시지에 담아서 전송합니다. 거의 모든 형태의 데이터를 전송 가능하고 서버 간 데이터를 주고받은 때도 대부분 HTTP 사용합니다.
HTTP/1.1 : 가장 많이 사용하고 중요합니다. 1.1 버전에 대부분 기능들이 나왔습니다.
HTTP/2와 HTTP/3도 나왔으나 이는 성능개선이 된 버전입니다.
TCP: HTTP/1.1, HTTP/2
UDP: HTTP/3을 기반으로 합니다.
페이지에서 f12로 확인해 보면 알 수 있든, HTTP/2나 HTTP/3을 사용하지만
학습 시 HTTP/1.1 스펙을 아는 것이 중요합니다.
HTTP 특징
- 클라이언트 서버 구조
- 무상태 프로토콜 지향(stateless), 비 연결성
- HTTP 메시지로 요청-응답
- 단순한 스펙, 확장 가능
클라이언트 서버 구조 (Request Response 구조)
클라이언트는 HTTP메시지를 서버로 요청을 보냅니다. 데이터를 찾고 서버는 요청에 대한 결과를 응답하는데요. 굉장히 단순한 구조지만, 이렇게 '클라이언트와 서버'를 개념적으로 분리하는 게 중요합니다. 복잡한 비즈니스 로직은 서버에, UI는 클라이언트가 관리하면 그 부분에만 집중하면 됩니다.
무상태 프로토콜(stateless)
서버가 클라이언트의 상태를 보존하지 않는다는 것입니다.
* 반대의 개념으론 상태 유지(stateful)가 있습니다. 서버가 클라이언트의 이전상태(context)를 보존합니다.
상태 유지, 무상태 어떤 게 다른 걸까요?
상태 유지의 경우 서버가 중간에 바뀌면 장애가 나게 되어서 항상 같은 서버가 유지되어야 합니다. 왜냐하면 서버가 바뀔 때마다 클라이언트의 상태 정보를 미리 알려줘야 하기 때문입니다.
무상태에서는 애초에 클라이언트가 요청할 때 정보를 다 담아서 요청하므로 아무 서버나 호출해도 괜찮습니다. 중간에 서버가 바뀌어도 아무 문제가 일어나지 않고 중간에 서버가 장애가 나도 다른 서버에서 처리가 가능합니다. 이러한 특징으로 갑자기 클라이언트 요청이 확 증가해도 서버 대거 투입이 가능하며 클라이언트 서버 아키텍처에서 무한한 확장성이 가능하게 되는 이유가 됩니다. = 스케일 아웃 = 수평 확장
그럼 무상태는 무적일까요? 그렇진 않습니다.
Stateless 한계
1. 모든 것을 무상태로 설계하면 좋겠지만, 가능하지 않은 경우도 존재합니다.
예를 들어 로그인의 경우 로그인 했다는 상태를 서버에 유지를 해야 합니다. 일반적으로 브라우저 쿠키와 서버 세션을 조합해서 상태를 유지합니다.
하지만, 상태 유지는 최소한으로 사용해야 합니다!
2. 요청할 때 많은 데이터를 가지고 요청합니다.
💡 스테이스리스
"시간이 정해져 있는 이벤트로 대용량 트래픽이 발생시 처리하는 업무"는 서버 개발자로 일하며 어려워하는 업무 중 하나 입니다.
예를 들어, 13시 선착순 1000명에게 피자 할인 이벤트, 연휴 KTX예약 등이 있습니다.
이때는 비 연결성이 필요가 없습니다. 사람들이 동시에 몰려오기 때문인데요.
최대한 스테이스리스로 설계하고 대용량 트래픽이 몰려올 때 서버를 증설해서 극복해야 합니다.
TIP)
첫 페이지 정적 페이지 (무상태, 한꺼번에 몰린 유저를 분산시키는 역할을 합니다. )
스크롤을 내려 이벤트 참여 버튼을 누르게 합니다.
비 연결성(connectionless)
기본적으로 TCP/IP는 연결을 유지합니다. (클라이언트 - 서버)
서버는 연결을 계속해서 유지하므로 서버 자원이 소모됩니다.
만약 연결을 유지하지 않는다면 어떨까요?
이 방법은 요청을 하고 응답을 받으면 TCP/IP 연결을 바로 끊어버리는 형태입니다. 이렇게 되면 서버입장에서는 연결을 유지할 필요가 없으므로 최소한의 자원을 사용합니다.
이런 방법이 비 연결성입니다.
* HTTP는 기본적으로 연결을 유지하지 않는 모델입니다.
그럼 1시간 동안 수천 명이 한 서비스를 이용한다고 해도 실 서버에서 동시에 처리하는 요청은 매우 작게 됩니다.
* 서버 자원을 매우 효율적으로 사용할 수 있습니다.
비 연결성 단점
1. TCP/IP 연결을 계속해서 새로 맺어야 합니다. 3 way handshake 시간 추가가 되므로 사용자 입장에서 단점이 됩니다.
2. 웹 브라우저에 사이트를 요청하면 단순하게 HTML 뿐만 아니라 CSS, 수많은 자료가 다운로드가 됩니다. 자원을 하나씩 연결하고 받고 끊고 하면 비효율적입니다.
지금은 HTTP에서 지속 연결((Persistent Connections)로 문제를 해결합니다.
* 클라이언트에서 서버로 연결 후,
HTML 요청 - 응답
이미지 요청 - 응답..... 계속해서 연결을 유지
종료
이번 포스팅의 마지막인 HTTP메시지에 대해 알아보겠습니다. 가장 중요한 파트이니 집중해서 공부해 보도록 하겠습니다.
HTTP 메시지
구조
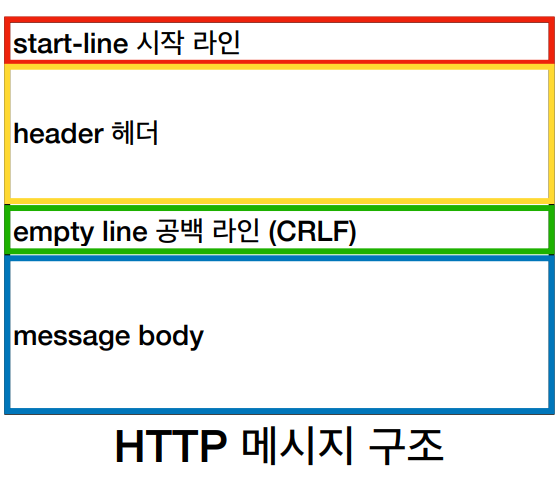
HTTP 요청과 응답 메시지 구조가 약간 다릅니다.
HTTP 요청 메시지

HTTP 응답 메시지
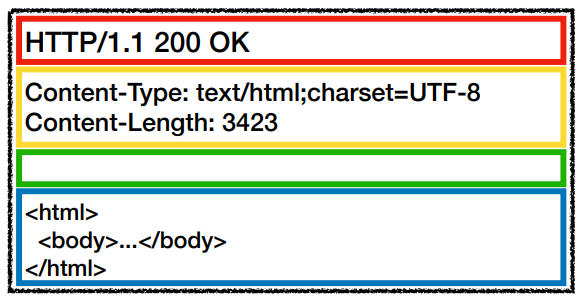
시작 라인
요청 메시지의 경우 시작 라인을 request-line이라고 합니다.
구조
- HTTP 메서드
- 요청 대상
- HTTP 버전
HTTP메서드 : GET, POST, PUT, DELETE...로 서버가 수행해야 할 동작을 지정합니다.
요청대상 : 절대경로로 시작하며 쿼리를 합친 형태입니다.
응답 메시지의 경우 시작 라인을 status-line이라고 합니다.
구조
- HTTP 버전
- HTTP 상태 코드 (요청 성공, 실패)
- 이유 문구로 짧은 상태 표시
HTTP 헤더
field-name: field value로 구성됩니다.
용도
1. HTTP 전송에 필요한 모든 부가 정보가 들어있습니다.
예) 메시지 바디의 내용, 크기 및 인증 정보 뿐만 아니라 브라우저 서버 정보, 캐시 관리 등
HTTP 메시지 바디
실제 전송할 데이터로 byte로 표현할 수 있는 모든 데이터 전송이 가능합니다.
[정리]
HTTP는 메시지에 모든 것을 전송하며 HTTP/1.1을 기준으로 스펙을 학습하면 됩니다.
클라이언트 서버 구조로, 무상태 프로토콜 특징을 가지고 있습니다.
HTTP는 요청, 응답 메시지 구조가 단순하며, 확장 가능한 파워풀한 기술입니다.
출처: https://www.inflearn.com/course/http-%EC%9B%B9-%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC/dashboard
'CS > Network' 카테고리의 다른 글
| [CS 스터디] 5주간의 네트워크 스터디 회고 (0) | 2024.12.02 |
|---|---|
| 실무에 꼭 필요한 HTTP - 1 (인터넷 네트워크) (1) | 2023.06.02 |
| HTTP 헤더 (HTTP Body, 표현, 협상, 쿠키) (0) | 2022.11.08 |